본 게시물은 AI를 활용하여 논문 “paper.doc”에 대한 주요 내용을 요약하고 분석한 결과입니다. 심층적인 정보는 원문 PDF를 직접 참고해 주시기 바랍니다.
📄 Original PDF: Download / View Fullscreen
영문 요약 (English Summary)
{Your English summary here}
한글 요약 (Korean Summary)
{귀하의 영어 요약 여기}
주요 기술 용어 설명 (Key Technical Terms)
이 논문의 핵심 개념을 이해하는 데 도움이 될 수 있는 주요 기술 용어와 그 설명을 제공합니다. 각 용어 옆의 링크를 통해 관련 외부 자료를 검색해 보실 수 있습니다.
- Mel Frequency Cepstal Coefficient (MFCC) [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
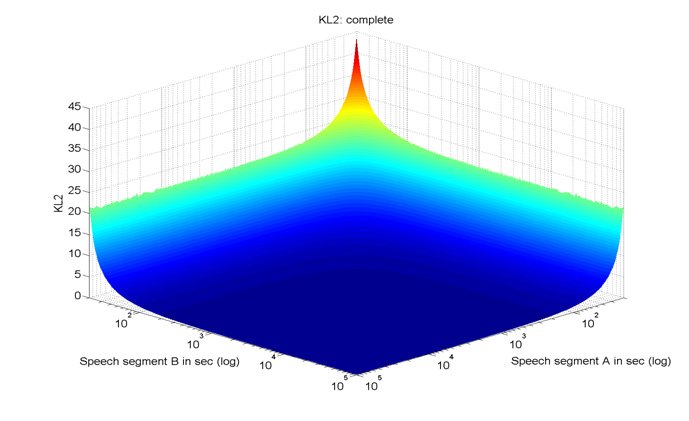
설명: 스피커 식별 및 추적에 적합한 오디오 세그먼트의 벡터 표현. 그것은 공분산 행렬, 평균 벡터 및 통계의 표준 오차를 기반으로하며, 표준 오류가 0으로 샘플이 무한대로 길다고 가정합니다. 가우스 혼합 모델이 더 적절하지만 폐쇄 형식 계산으로 인한 분석적 어려움을 나타냅니다.
(Original: Vector representation of audio segments, suitable for speaker identification and tracking. It is based on the covariance matrix, mean vector, and standard errors of their statistics, which assumes that samples are infinitely long with zero standard error. A Gaussian mixture model would be more appropriate but presents analytic difficulties due to its closed-form computation.) - Kullback Leibler distance (KL2) [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: 통계적 측정은 두 가지 중요한 가정하에 도출 된 MEL 주파수 CEPSTAL 계수 기능 벡터의 비교를 기반으로 스피커 클러스터링에서 자주 사용 된 통계적 측정 : 첫째, MFCC 벡터는 d 차원 가우시안으로 분포된다; 둘째, 그 샘플 평균과 공분산은 인구 평균과 공분산의 완벽한 추정치입니다.
(Original: Statistical measure used frequently in speaker clustering based on comparison of Mel Frequency Cepstal Coefficient feature vectors, derived under two critical assumptions: first, that the MFCC vectors are distributed as a d-dimensional Gaussian; second, that sample means and covariances are perfect estimators of population means and covariances.) - Vector Quantization (VQ) [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: 스피커 추출 기능 벡터에 대한 벡터 양자화에 기초한 방법. 비대칭 KL 거리 TR (σB-1 σA)으로 인해 음성 세그먼트 B의 길이에 강력하게 반응하여 가우시안 혼합 모델은 더 적절하지만 폐쇄 형식 계산으로 인해 분석적 어려움을 나타냅니다.
(Original: Method based on vector quantization for speaker extracted feature vectors. It outlines the source of length effect due to its asymmetric KL distance tr(σB−1 σA) responding strongly to speech segment B’s length, while Gaussian mixture model is more appropriate but presents analytic difficulties due to its closed-form computation.)
원문 발췌 및 번역 보기 (Excerpt & Translation)
원문 발췌 (English Original)
ACCOMMODATING SAMPLE SIZE EFFECT ON SIMILARITY MEASURES IN SPEAKER CLUSTERING Alexander Haubold and John R. Kender Department of Computer Science, Columbia University ABSTRACT seconds) exhibits large degradation in performance. We also show that a similar effect exists for comparisons between We investigate the symmetric Kullback-Leibler (KL2) differently-sized feature segments. We have observed distance in speaker clustering and its unreported effects for decreasing accuracy the larger the difference in length of differently-sized feature matrices. Speaker data is two audio segments. represented as Mel Frequency Cepstral Coefficient (MFCC) We evaluate two alternative speaker clustering vectors, and features are compared using the KL2 metric to approaches based on vector quantization. The method form clusters of speech segments for each speaker. We proposed in [10] as a closed-form solution to KL2 for image make two observations with respect to clustering based on comparison exhibits a similar trend in sample size effect. KL2: 1.) The accuracy of clustering is strongly dependent Smaller sets of features generally result in less accurate on the absolute lengths of the speech segments and their comparisons. A modified version of VQ for speaker extracted feature vectors. 2.) The accuracy of the similarity identification [6] explicitly takes into consideration a measure strongly degrades with the length of the shorter of correcting factor for sample size. Comparisons based on this the two speech segments. These effects of length can be measure show less biased results with respect to the size of attributed to the measure of covariance used in KL2. We a speaker’s feature set. demonstrate an empirical correction of this sample-size effect that increases clustering accuracy. We draw parallels 2. BACKGROUND to two Vector Quantization-based (VQ) similarity measures, one which exhibits an equivalent effect of sample size, and The KL2 distance is used frequently in the context of the second being…
발췌문 번역 (Korean Translation)
스피커 클러스터링의 유사성 측정에 대한 샘플 크기 효과를 수용하는 Alexander Haubold와 John R. Kender Computer Science Department, Columbia University Abstract Sec 우리는 또한 대칭 kullback-leibler (KL2)의 다른 크기의 기능 세그먼트를 조사하는 것 사이의 비교를 위해 유사한 효과가 있음을 보여줍니다. 우리는 스피커 클러스터링의 거리와 정확도 감소를 위해보고되지 않은 효과를 관찰했습니다. 스피커 데이터는 두 개의 오디오 세그먼트입니다. MEL 주파수 CEPSTRAL COEFFICE (MFCC)로 표현되어 두 개의 대체 스피커 클러스터링 벡터를 평가하고 KL2 메트릭을 사용하여 벡터 양자화에 기초한 접근법을 사용하여 특징을 비교합니다. 이 방법은 각 스피커에 대한 음성 세그먼트의 클러스터를 형성합니다. 우리는 [10]에서 이미지에 대한 KL2에 대한 폐쇄 형 용액으로서 [10]에서 비교에 기초한 클러스터링과 관련하여 두 가지 관찰을하는 것은 표본 크기 효과에서 유사한 경향을 나타낸다. KL2 : 1.) 클러스터링의 정확도는 강력하게 의존적이며 작은 기능 세트는 일반적으로 음성 세그먼트의 절대 길이와 비교에 덜 정확하지 않습니다. 스피커 추출 기능 벡터 용 VQ의 수정 된 버전. 2.) 유사성 식별의 정확성 [6]은 샘플 크기에 대한 수정 계수의 짧은 길이에 따라 측정 값을 크게 저하시키는 것을 명시 적으로 고려한다. 이를 기반으로 비교 두 가지 음성 세그먼트. 이러한 길이의 영향은 KL2에 사용 된 공분산 측정에 기인 한 크기와 관련하여 덜 바이어스 된 결과를 보여줄 수 있습니다. 우리는 스피커의 기능 세트입니다. 클러스터링 정확도를 증가시키는이 샘플 크기 효과의 경험적 보정을 보여줍니다. 우리는 2 개의 벡터 양자화 기반 (VQ) 유사성 측정에 대한 배경을 그립니다.이 측정 값은 샘플 크기의 동등한 효과를 나타내며 KL2 거리는 두 번째 존재의 맥락에서 자주 사용됩니다.
출처(Source): arXiv.org (또는 해당 논문의 원 출처)
답글 남기기