Summary (English)
This scientific paper explores Data-Driven Self-Supervised Graph Representation Learning, a novel approach to reduce or avoid manual labeling in representation learning.
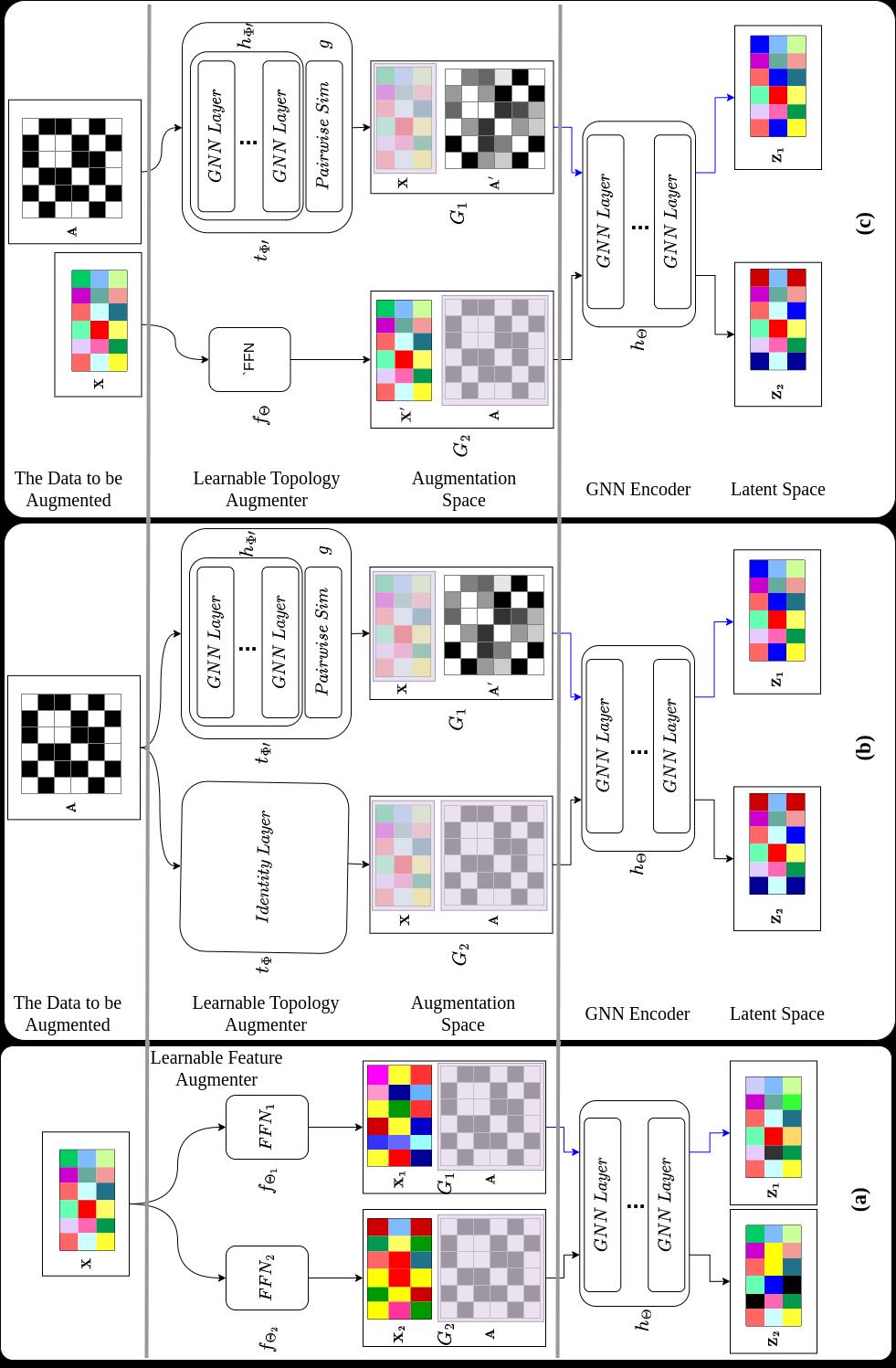
The main objective is to learn high-quality representations by automatically discovering suitable graph augmentation from the signal encoded within the graph’s nodes and topology.
Two complementary approaches are proposed: one for feature augmentation and another for topological augmentation, which can be applied to both homogeneous and heterogeneous graphs.
The authors argue that existing self-supervised methods often rely on heuristics that may only work well in specific domains or applications.
By learning the augmentation process from data, this approach aims to provide a more flexible framework adaptable across various domains while avoiding trial and error in identifying suitable augmentation techniques.
Extensive experiments demonstrate the effectiveness of the proposed method compared to state-of-the-art self-supervised methods and semi-supervised approaches.
The main objective is to learn high-quality representations by automatically discovering suitable graph augmentation from the signal encoded within the graph’s nodes and topology.
Two complementary approaches are proposed: one for feature augmentation and another for topological augmentation, which can be applied to both homogeneous and heterogeneous graphs.
The authors argue that existing self-supervised methods often rely on heuristics that may only work well in specific domains or applications.
By learning the augmentation process from data, this approach aims to provide a more flexible framework adaptable across various domains while avoiding trial and error in identifying suitable augmentation techniques.
Extensive experiments demonstrate the effectiveness of the proposed method compared to state-of-the-art self-supervised methods and semi-supervised approaches.
요약 (Korean)
이 과학 논문은 표현 학습의 수동 라벨링을 줄이거 나 피하기위한 새로운 접근법 인 데이터 중심의 자기 감독 그래프 표현 학습을 탐구합니다.
주요 목표는 그래프의 노드 및 토폴로지 내에서 인코딩 된 신호에서 적절한 그래프 확대를 자동으로 발견하여 고품질 표현을 배우는 것입니다.
두 가지 보완적인 접근법이 제안된다 : 하나는 특징 확대 및 토폴로지 확대를위한 것이며, 이는 균질 한 및 이질적인 그래프에 적용될 수있다.
저자는 기존의 자기 감독 방법이 종종 특정 영역이나 응용 분야에서만 잘 작동 할 수있는 휴리스틱에 의존한다고 주장합니다.
이 접근법은 데이터에서 증강 프로세스를 학습함으로써 다양한 도메인에 걸쳐보다 유연한 프레임 워크를 제공하면서 적절한 증강 기술을 식별하는 시행 착오를 피하는 것을 목표로합니다.
광범위한 실험은 최첨단 자체 감독 방법 및 반 감독 접근법과 비교하여 제안 된 방법의 효과를 보여줍니다.
주요 목표는 그래프의 노드 및 토폴로지 내에서 인코딩 된 신호에서 적절한 그래프 확대를 자동으로 발견하여 고품질 표현을 배우는 것입니다.
두 가지 보완적인 접근법이 제안된다 : 하나는 특징 확대 및 토폴로지 확대를위한 것이며, 이는 균질 한 및 이질적인 그래프에 적용될 수있다.
저자는 기존의 자기 감독 방법이 종종 특정 영역이나 응용 분야에서만 잘 작동 할 수있는 휴리스틱에 의존한다고 주장합니다.
이 접근법은 데이터에서 증강 프로세스를 학습함으로써 다양한 도메인에 걸쳐보다 유연한 프레임 워크를 제공하면서 적절한 증강 기술을 식별하는 시행 착오를 피하는 것을 목표로합니다.
광범위한 실험은 최첨단 자체 감독 방법 및 반 감독 접근법과 비교하여 제안 된 방법의 효과를 보여줍니다.
기술적 용어 설명 (Technical Terms)
추출된 기술 용어가 없습니다.
Excerpt (English Original)
Data-Driven Self-Supervised Graph Representation Learning Ahmed E.
Samya;*, Zekarias T.
Kefatoa and Šar¯unas Girdzijauskasa aKTH, Royal Institute of Technology, Stockholm, Sweden aesy@kth.se, zekarias@kth.se, sarunasg@kth.se Abstract.
Self-supervised graph representation learning (SSGRL) is a a meaningful perturbation on the original data point.
The representation representation learning paradigm used to reduce or avoid manual labeling.
of a data point is then learned by maximizing the mutual information An essential part of SSGRL is graph data augmentation.
Existing methods between latent representations obtained from its augmented views.
The usually rely on heuristics commonly identified through trial and error main challenge here is to produce augmented views of the data points.
and are effective only within some application domains.
Also, it is not The key to learning high-quality representations based on augmenta- clear why one heuristic is better than another.
Moreover, recent studies tion is that the perturbations should preserve semantics [1,6,38,49].
For have argued against some techniques (e.g., dropout: that can change the instance, a perturbation applied to an image of a dog should preserve properties of molecular graphs or destroy relevant signals for graph-based “dogness”.
Effective augmentation techniques for images (e.g., rotation, flip- document classification tasks).
ping, resizing) allow learning high-quality visual representations because2024 In this study, we propose a novel data-driven SSGRL approach that au- they preserve the semantics of the original image.
This is also true for SSL tomatically learns a suitable graph augmentation from the signal encoded techniques in NLP [7,21,23], (e.g.
synonym augmentation and word mask- in the graph (i.e., the nodes’ predictive feature and topological informa- ing), such techniques do not alter the meaning of the original sentence.
tion).
We propose two complementary approaches that produce learnable Due to the complex nature of graph data, it is much more challengingDec feature and topological augmentations.
The former learns multi-view…
Samya;*, Zekarias T.
Kefatoa and Šar¯unas Girdzijauskasa aKTH, Royal Institute of Technology, Stockholm, Sweden aesy@kth.se, zekarias@kth.se, sarunasg@kth.se Abstract.
Self-supervised graph representation learning (SSGRL) is a a meaningful perturbation on the original data point.
The representation representation learning paradigm used to reduce or avoid manual labeling.
of a data point is then learned by maximizing the mutual information An essential part of SSGRL is graph data augmentation.
Existing methods between latent representations obtained from its augmented views.
The usually rely on heuristics commonly identified through trial and error main challenge here is to produce augmented views of the data points.
and are effective only within some application domains.
Also, it is not The key to learning high-quality representations based on augmenta- clear why one heuristic is better than another.
Moreover, recent studies tion is that the perturbations should preserve semantics [1,6,38,49].
For have argued against some techniques (e.g., dropout: that can change the instance, a perturbation applied to an image of a dog should preserve properties of molecular graphs or destroy relevant signals for graph-based “dogness”.
Effective augmentation techniques for images (e.g., rotation, flip- document classification tasks).
ping, resizing) allow learning high-quality visual representations because2024 In this study, we propose a novel data-driven SSGRL approach that au- they preserve the semantics of the original image.
This is also true for SSL tomatically learns a suitable graph augmentation from the signal encoded techniques in NLP [7,21,23], (e.g.
synonym augmentation and word mask- in the graph (i.e., the nodes’ predictive feature and topological informa- ing), such techniques do not alter the meaning of the original sentence.
tion).
We propose two complementary approaches that produce learnable Due to the complex nature of graph data, it is much more challengingDec feature and topological augmentations.
The former learns multi-view…
발췌문 (Korean Translation)
Ahmed E.
Samya;*, Zekarias T.
Kefatoa 및 Šar¯unas Girdzijauskasa Akth, Royal Institute, Stockholm, Sweden aesy@kth.se, zekarias@kth.se, sarunasg@kth.se toplart.
SSGRL (Self-Supervedied Graph 표현 학습)은 원래 데이터 포인트에서 의미있는 섭동입니다.
표현 표현 학습 패러다임은 수동 라벨링을 줄이거 나 피하는 데 사용됩니다.
그런 다음 상호 정보를 최대화하여 데이터 포인트를 학습합니다.
SSGRL의 필수 부분은 그래프 데이터 증강입니다.
증강 된 견해에서 얻은 잠재적 표현 사이의 기존 방법.
일반적으로 시행 착오를 통해 일반적으로 식별되는 휴리스틱에 의존하는 것은 여기서 주요 과제는 데이터 포인트의 증강 견해를 생성하는 것입니다.
일부 응용 프로그램 도메인 내에서만 효과적입니다.
또한, 하나의 휴리스틱이 다른 휴리스틱보다 더 나은 이유를 확고한 고품질 표현을 배우는 것은 열쇠가 아닙니다.
더욱이, 최근의 연구는 섭동이 의미론을 보존해야한다는 것이다 [1,6,38,49].
일부 기술에 대해 논쟁했기 때문에 (예 : 드롭 아웃 : 인스턴스를 바꿀 수 있습니다.
개의 이미지에 적용되는 섭동은 분자 그래프의 특성을 보존하거나 그래프 기반의“개”에 대한 관련 신호를 파괴해야합니다.
이미지에 대한 효과적인 증강 기술 (예 : 회전, 플립-문서 분류 작업).
데이터 중심의 SSGRL 접근 방식은 원본 이미지의 의미를 보존합니다.
이것은 SSL이 NLP의 신호 인코딩 된 기술로부터 적절한 그래프 확대를 배우는 경우에도 해당됩니다 [7,21,23] (예 : 그래프에서 동의어 증강 및 단어 마스크) (즉, 노드의 예측 특징과 토폴로지 정보 정보).
그러한 기술은 원래 문장의 의미를 바꾸지 않습니다.
우리는 그래프 데이터의 복잡한 특성으로 인해 학습 할 수있는 두 가지 보완 접근법을 제안합니다.
이는 훨씬 더 어려운 DEC 기능 및 토폴로지 증강입니다.
전자는 멀티 뷰를 배웁니다 …
Samya;*, Zekarias T.
Kefatoa 및 Šar¯unas Girdzijauskasa Akth, Royal Institute, Stockholm, Sweden aesy@kth.se, zekarias@kth.se, sarunasg@kth.se toplart.
SSGRL (Self-Supervedied Graph 표현 학습)은 원래 데이터 포인트에서 의미있는 섭동입니다.
표현 표현 학습 패러다임은 수동 라벨링을 줄이거 나 피하는 데 사용됩니다.
그런 다음 상호 정보를 최대화하여 데이터 포인트를 학습합니다.
SSGRL의 필수 부분은 그래프 데이터 증강입니다.
증강 된 견해에서 얻은 잠재적 표현 사이의 기존 방법.
일반적으로 시행 착오를 통해 일반적으로 식별되는 휴리스틱에 의존하는 것은 여기서 주요 과제는 데이터 포인트의 증강 견해를 생성하는 것입니다.
일부 응용 프로그램 도메인 내에서만 효과적입니다.
또한, 하나의 휴리스틱이 다른 휴리스틱보다 더 나은 이유를 확고한 고품질 표현을 배우는 것은 열쇠가 아닙니다.
더욱이, 최근의 연구는 섭동이 의미론을 보존해야한다는 것이다 [1,6,38,49].
일부 기술에 대해 논쟁했기 때문에 (예 : 드롭 아웃 : 인스턴스를 바꿀 수 있습니다.
개의 이미지에 적용되는 섭동은 분자 그래프의 특성을 보존하거나 그래프 기반의“개”에 대한 관련 신호를 파괴해야합니다.
이미지에 대한 효과적인 증강 기술 (예 : 회전, 플립-문서 분류 작업).
데이터 중심의 SSGRL 접근 방식은 원본 이미지의 의미를 보존합니다.
이것은 SSL이 NLP의 신호 인코딩 된 기술로부터 적절한 그래프 확대를 배우는 경우에도 해당됩니다 [7,21,23] (예 : 그래프에서 동의어 증강 및 단어 마스크) (즉, 노드의 예측 특징과 토폴로지 정보 정보).
그러한 기술은 원래 문장의 의미를 바꾸지 않습니다.
우리는 그래프 데이터의 복잡한 특성으로 인해 학습 할 수있는 두 가지 보완 접근법을 제안합니다.
이는 훨씬 더 어려운 DEC 기능 및 토폴로지 증강입니다.
전자는 멀티 뷰를 배웁니다 …
출처: arXiv
답글 남기기