본 게시물은 AI를 활용하여 논문 “Algorithmic Strategies for Sustainable Reuse of Neural Network Accelerators with Permanent Faults”에 대한 주요 내용을 요약하고 분석한 결과입니다. 심층적인 정보는 원문 PDF를 직접 참고해 주시기 바랍니다.
📄 Original PDF: Download / View Fullscreen
영문 요약 (English Summary)
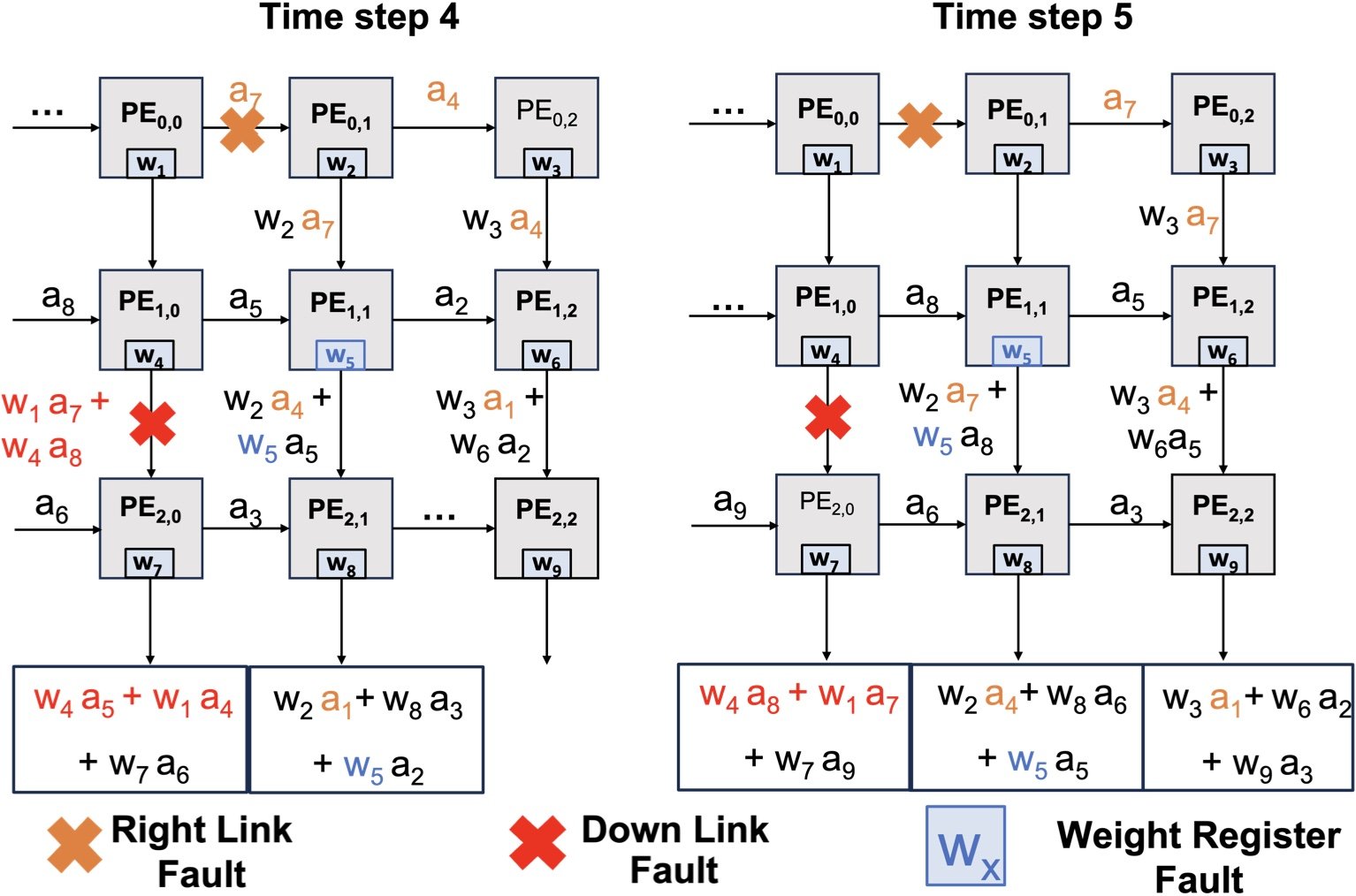
This paper focuses on developing algorithmic approaches that mitigate permanent hardware faults in neural network (NN) accelerators by uniquely integrating the behavior of faulty components. The proposed algorithms work with existing components of widely used systolic array based accelerators, such as normalization, curacy for stuck-at faults at particular bit positions under var- storage units, fine-tuning a NN to incorporate the behavior of hardware faults. Extensive experimental evaluations using fully connected and convolutional neural networks trained on MNST, CIFAR-10 and ImageNet datasets show that proposed fault-tolerant techniques match or get very close to original fault-free accuracy for all floating point representations tested.
한글 요약 (Korean Summary)
이 논문은 결함 구성 요소의 동작을 고유하게 통합하여 NN (Neural Network) 가속기에서 영구 하드웨어 결함을 완화하는 알고리즘 접근법 개발에 중점을 둡니다. 제안 된 알고리즘은 널리 사용되는 수축기 배열 기반 가속기의 기존 구성 요소, 예를 들어 정규화, 가변 저장 장치의 특정 비트 위치에서 고정 결함에 대한 치료법과 같은 하드웨어 결함의 동작을 통합하기 위해 미세 조정합니다. MNST, CIFAR-10 및 ImageNet 데이터 세트에서 훈련 된 완전히 연결되고 컨 컨트리 신경 네트워크를 사용한 광범위한 실험 평가는 제안 된 결함 내성 기술이 테스트 된 모든 부동 소수점 표현에 대해 원래 결함이없는 정확도에 매우 가까워지는 것을 보여줍니다.
주요 기술 용어 설명 (Key Technical Terms)
이 논문의 핵심 개념을 이해하는 데 도움이 될 수 있는 주요 기술 용어와 그 설명을 제공합니다. 각 용어 옆의 링크를 통해 관련 외부 자료를 검색해 보실 수 있습니다.
- Algorithmic methods [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: var-Storage 단위의 정규화 및 치료와 같은 널리 사용되는 Systoli Array 기반 가속기의 기존 구성 요소를 사용하여 하드웨어 고장을 완화하는 새로운 접근 방식. 이러한 기술을 통해 NN을 미세 조정하여 결함이있는 하드웨어의 동작을 통합 할 수 있습니다. MNST, CIFAR-10 및 ImageNet 데이터 세트에서 훈련 된 완전히 연결되고 컨 컨트리 신경 네트워크를 사용한 광범위한 실험 평가는 제안 된 결함 허용 기술이 테스트 된 모든 부동 소수점 표현에 대해 원래 결함이없는 정확도에 매우 가까워지는 것을 보여줍니다.
(Original: Novel approaches that mitigate hardware failures by utilizing existing components of widely used systoli array based accelerators, such as normalization and curacy under var-storage units. These techniques enable fine tuning a NN to incorporate the behavior of faulty hardware. Extensive experimental evaluations using fully connected and convolutional neural networks trained on MNST, CIFAR-10 and ImageNet datasets show that proposed fault tolerant techniques match or get very close to original fault free accuracy for all floating point representations tested.) - Neural network accelerators [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: 많은 양의 데이터를 효율적으로 처리하기 위해 병렬 처리를 기반으로 NN 가속기와 같은 기계 학습 응용 프로그램을 위해 특별히 설계된 하드웨어 구성 요소에는 널리 사용되는 TPU [54] 및 NVDLA와 같은 SIMD 가속기가 포함됩니다 [55]. 이 가속기는 알고리즘 완화 기술이 필요한 하드웨어 고장에 취약합니다.
(Original: Hardware components designed specifically for machine learning applications such as NN accelerators based on parallelism in order to efficiently process large amounts of data, examples include widely used TPU [54] and SIMD accelerators like NVDLA [55]. These accelerators are susceptible to hardware failures that require algorithmic mitigation techniques.) - Hardware faults [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: 머신 러닝 응용 프로그램에서보고 된 과도 또는 영구 실패와 같은 예기치 않은 하드웨어 오류로 인한 예상치 못한 결과, 특히 NNS가보고 된 경우의 수많은 사례를 초래하는 신경 네트워크 가속기 [15], [20], [21]. var-Storage 유닛 하에서 특정 비트 위치에서 고정 결함의 영향을 특성화하면 하드웨어 결함 동작을 통합하기 위해 NN을 미세 조정하는 것을 단순화합니다.
(Original: Unexpected results caused by unexpected hardware errors such as transient or permanent failures reported in machine learning applications, specifically neural network accelerators based on parallelism leading to an increasing number of instances where NNs have been reported [15], [20], [21]. Characterizing the impact of stuck-at faults at specific bit positions under var-storage units simplifies fine tuning a NN to incorporate hardware fault behavior.) - Stuck-at faults [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: 머신 러닝 응용 프로그램에서보고 된 일시적 또는 영구적 인 실패로 인한 예기치 않은 결과로 인해 발생하는 하드웨어 오류, 특히 NNS 가보고 된 경우의 수많은 사례를 초래하는 신경 네트워크 가속기 [15], [20], [21]. var-storage 유닛 하에서 특정 비트 위치에서 고정 결함을 특성화하면 하드웨어 결함 동작을 통합하기 위해 NN을 미세 조정하는 것을 단순화합니다.
(Original: Hardware errors that occur due to unexpected results caused by either transient or permanent failures reported in machine learning applications, specifically neural network accelerators based on parallelism leading to an increasing number of instances where NNs have been reported [15], [20], [21]. Characterizing stuck-at faults at specific bit positions under var-storage units simplifies fine tuning a NN to incorporate hardware fault behavior.) - PyTorch [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: 알고리즘 완화 기술, 특히 NNS 가보고 된 사례를 증가시키는 평행을 기반으로 한 신경망 가속기에 사용되는 오픈 소스 머신 러닝 프레임 워크 [15], [20], [21]. var-storage 유닛 하에서 특정 비트 위치에서 고정 결함을 특성화하면 하드웨어 결함 동작을 통합하기 위해 NN을 미세 조정하는 것을 단순화합니다.
(Original: An open source machine learning framework used for algorithmic mitigation techniques, specifically neural network accelerators based on parallelism leading to an increasing number of instances where NNs have been reported [15], [20], [21]. Characterizing stuck-at faults at specific bit positions under var-storage units simplifies fine tuning a NN to incorporate hardware fault behavior.) - Tensor operations [Wikipedia (Ko)] [Wikipedia (En)] [나무위키] [Google Scholar] [Nature] [ScienceDirect] [PubMed]
설명: A. A.를 사용하여 PES가 수행하는 작업은 CudapyTorch 텐서 작업을 사용하여 결함 주입을위한 고성능 시스템 어레이 어레이를 사용하여 C를 구성합니다.
(Original: Operations performed by PEs using A. High Performance Systoli Arrays for fault injection using CUDAPyTorch tensor operations, thus constructing a c)
원문 발췌 및 번역 보기 (Excerpt & Translation)
원문 발췌 (English Original)
Algorithmic Strategies for Sustainable Reuse of Neural Network Accelerators with Permanent Faults Youssef A. Ait Alama†, Sampada Sakpal†, Ke Wang†, Razvan Bunescu†, Avinash Karanth‡, and Ahmed Louri¶ University of North Carolina at Charlotte†, Ohio University‡, The George Washington University¶ Corresponding Author∗ yaitalam@charlotte.edu Abstract—Hardware failures are a growing challenge for healthy devices [6]. In the case of permanent faults, which machine learning accelerators, many of which are based on is the focus of this paper, a bit stuck at 0 or 1 in a link systolic arrays. When a permanent hardware failure occurs in a between PEs or within a TPU-internal buffer may render systolic array, existing solutions include localizing and isolating2024 the component unusable in critical applications. Discarding the faulty processing element (PE), using a redundant PE for re-execution, or in some extreme cases decommissioning the a faulty component or bypassing it is a wasteful decision and entire accelerator for further investigation. In this paper, we forms part of the linear economy pattern of create-use-dispose,Dec propose novel algorithmic approaches that mitigate permanent a manufacturing approach that is unsustainable [25]. Disposing hardware faults in neural network (NN) accelerators by uniquely of a faulty component is also impractical in situations where integrating the behavior of the faulty component instead of17 the hardware cannot be easily replaced, for instance if it is bypassing it. In doing so, we aim for a more sustainable use of the accelerator where faulty hardware is neither bypassed nor already deployed in an artificial satellite or a space station. discarded, instead being given a second life. We first introduce The downtime incurred in replacing faulty hardware can also a CUDA-accelerated systolic array simulator in PyTorch, which become significant, particularly for high error rates. Therefore, enabled us to quantify the impact of permanent faults appearing it is imperative to…
발췌문 번역 (Korean Translation)
영구적 인 결함을 가진 신경 네트워크 가속기의 지속 가능한 재사용을위한 알고리즘 전략 Youssef A. Ait Alama †, Sampada Sakpal †, Ke Wang †, Razvan Bunescu †, Avinash Karanth ‡ 및 Ohio University에서 노스 캐롤라이나 대학교의 Ahmed Louri †에 해당합니다. yaitalam@charlotte.edu 초록 – 하드웨어 고장은 건강한 장치의 경우 점점 더 많은 어려움을 겪고 있습니다 [6]. 기계 학습 가속기가있는 영구적 인 결함의 경우, 많은 것이이 논문의 초점이며, 링크 수축기 어레이에서 0 또는 1에 약간 붙어 있습니다. 영구 하드웨어 고장이 PES 사이 또는 TPU 내부 버퍼 내에서 A에서 발생할 때 수축기 어레이를 렌더링 할 수있는 경우, 기존 솔루션에는 현지화 및 분리 2024가 중요 응용 프로그램에서는 사용할 수 없습니다. 결함이있는 처리 요소 (PE), 재 실행을위한 중복 PE를 사용하거나, 일부 경우에도 결함이있는 구성 요소를 해체하거나 우회하는 경우 추가 조사를위한 낭비적인 결정 및 전체 가속기입니다. 이 논문에서, 우리는 생성 사용 이용의 선형 경제 패턴의 일부를 형성하며, DEC는 지속 불가능한 제조 접근 방식을 완화하는 새로운 알고리즘 접근법을 제안한다 [25]. 신경 네트워크 (NN)의 하드웨어 결함 처분 결함이있는 구성 요소의 고유 한 구성 요소에 의한 하드웨어 결함은 17 대신 결함이있는 구성 요소의 동작을 통합 할 수없는 상황에서는 실용적이지 않습니다. 그렇게함으로써, 우리는 결함이있는 하드웨어가 인공 위성이나 우주 정거장에 우회하거나 이미 배치되지 않은 가속기의보다 지속 가능한 사용을 목표로합니다. 폐기, 대신 두 번째 삶이 주어졌습니다. 우리는 먼저 결함이있는 하드웨어를 대체 할 때 발생하는 다운 타임을 Pytorch의 Cuda-Accelerated 수축기 배열 시뮬레이터로 대체하여 특히 높은 오류율에 대해 중요 해집니다. 따라서 영구 결함의 영향을 정량화 할 수있게 해주었습니다.
출처(Source): arXiv.org (또는 해당 논문의 원 출처)
답글 남기기